
Neon - a hardware definition language
A hardware definition language with a minimalist, functional style syntax in order to lower the barrier of high performance hardware design
Abstract Research of Computer Architecture
We are the Abstract Research of Computer Architecture group. We generally explore novel computational systems with low-level applications and more. Our work spans fundamental microarchitecture, memory hierarchies, interconnects, and the co-design of hardware with compilers and runtimes to unlock efficiency and reliability at scale.
Applied research bridging theory and real systems—validated on simulators, FPGA prototypes, and silicon when feasible.
Focus on low-level applications: graph analytics, ML inference, secure boot, and telemetry-driven optimization.
Open science ethos: publishing specs, datasets, and code where possible to accelerate community progress.
Areas of Inquiry
A hardware definition language with a minimalist, functional style syntax in order to lower the barrier of high performance hardware design
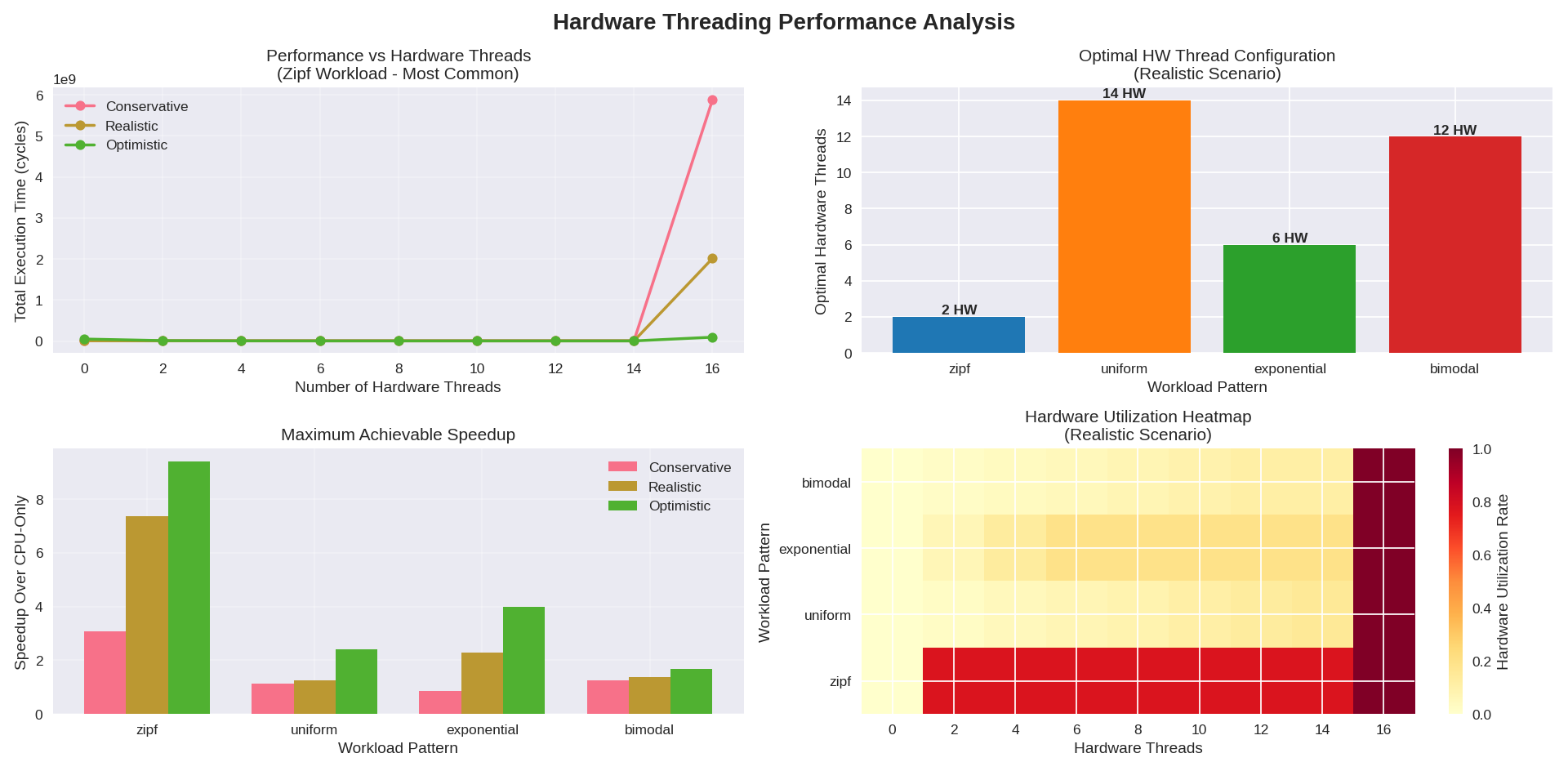
combining the best of both from FPGAs and classic fetch-execute style computation to optimise performance across dynamic workloads
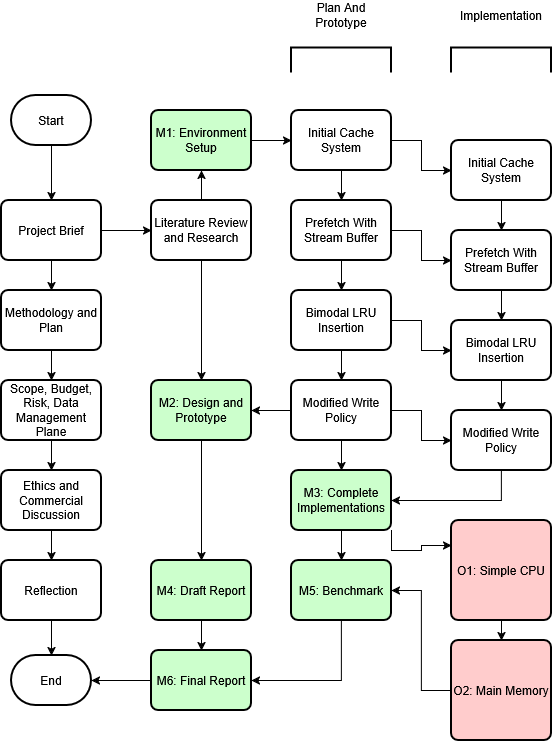
looking at using free bus resources to update cache lines in order to get the most from update and invalidate based coherency protocols.
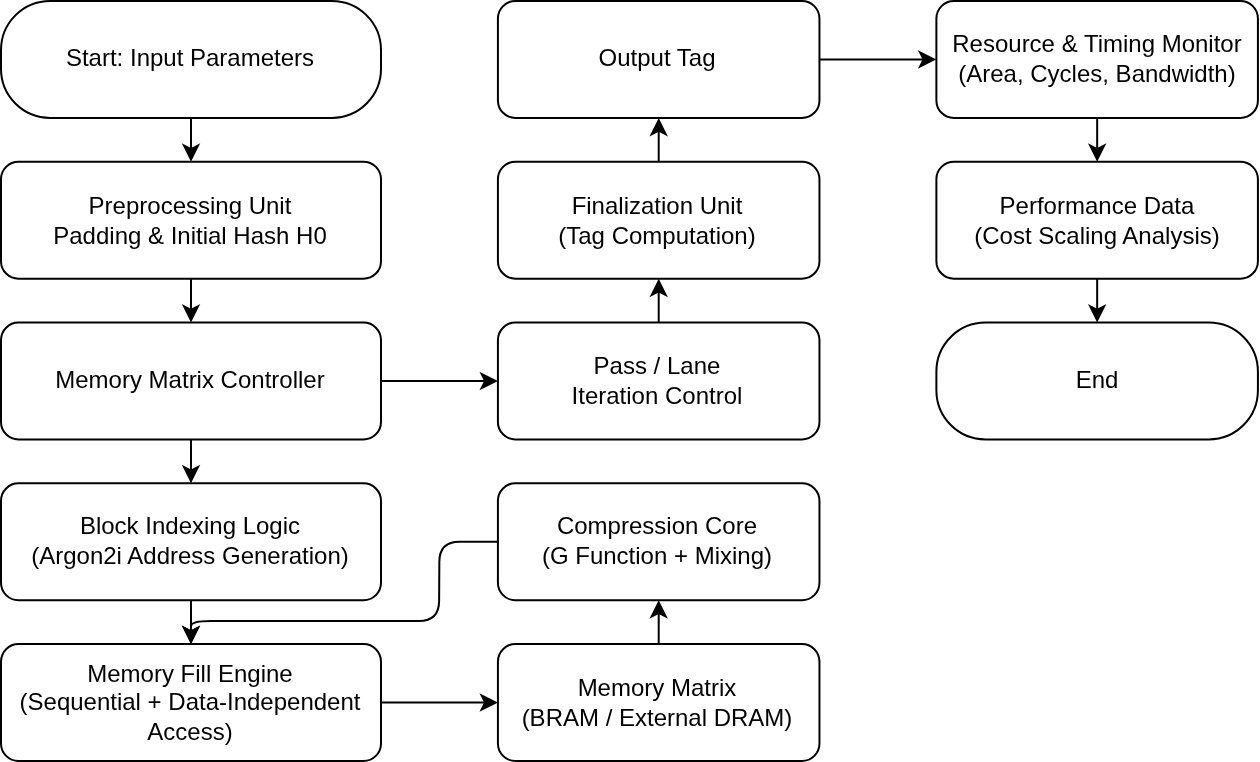
argon2i hash security tested with fpga attacks. measuring practical adversary cost scaling for password protection.
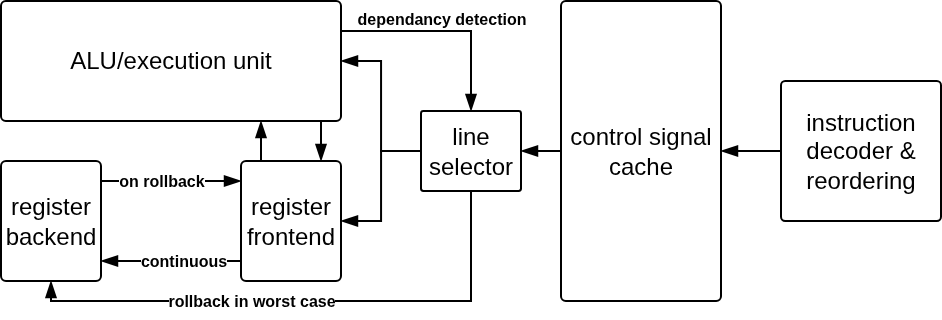
researching novel instruction reordering concepts for use in lightweight, out of order, superscalar architectures
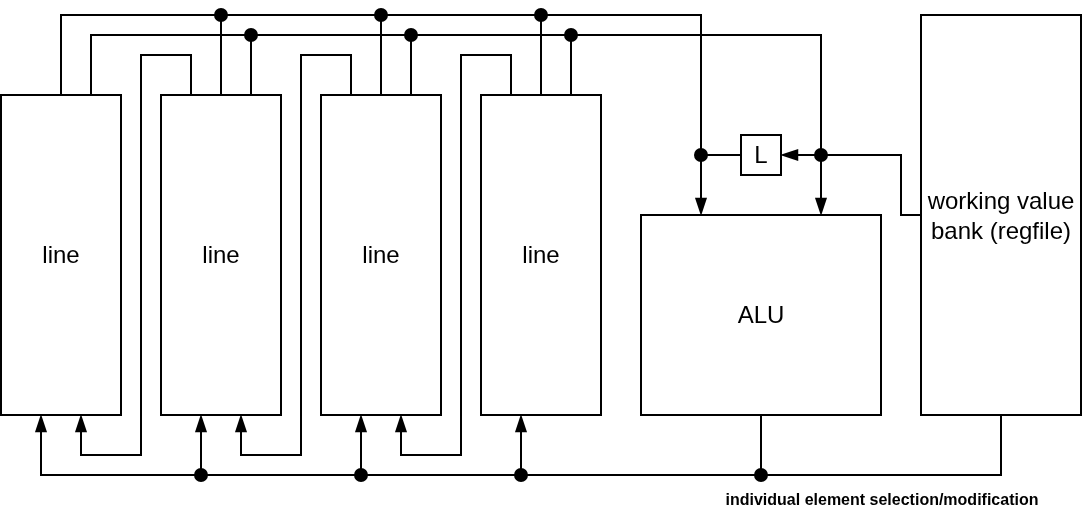
adapting features from functional programming and other mediums to design an efficient SIMD processor